作者: 邙嘉璐 ,来源:网络交换FPGA
10G以太网光口与高速串行接口的使用越来越普遍,本文拟通过一个简单的回环实验,来说明在常见的接口调试中需要注意的事项。各种Xilinx FPGA接口学习的秘诀:Example Design。欢迎探讨。
一、实验目的
为实现大容量交换机与高速率通信设备之间的高效数据传输,高速接口的理解与使用愈发显现出其重要地位。本实验设计中计划使用四个GTH高速串行接口,分别采用了10G以太网接口协议以及Aurora64b66b接口协议,实现交换板到测试设备的连接并通过光纤实现高速数据片外回环,以达到快速理解接口协议并能够熟练使用该两种高速接口实现数据收发的目的。
二、接口简介
1、 GT接口简介
应用在高速串行接口的数据收发。在A7系列芯片中叫GTP、在K7系列叫GTX、V7系列叫GTH,对于不同速度等级的高速通信的物理接口,原理基本一致。
1.1、收发器结构
对于每一个串行高速收发器,其分为两个子层:PCS(物理编码子层)和 PMA(物理媒体连接子层)。PCS 层主要进行数据编解码以及多通道的处理;PMA 层主要进行串并、并串转换,预加重、去加重,串行数据的发送、数据时钟的提取。可以使用ibert IP核对接口进行回环测试,确定该接口是否可以正常使用。
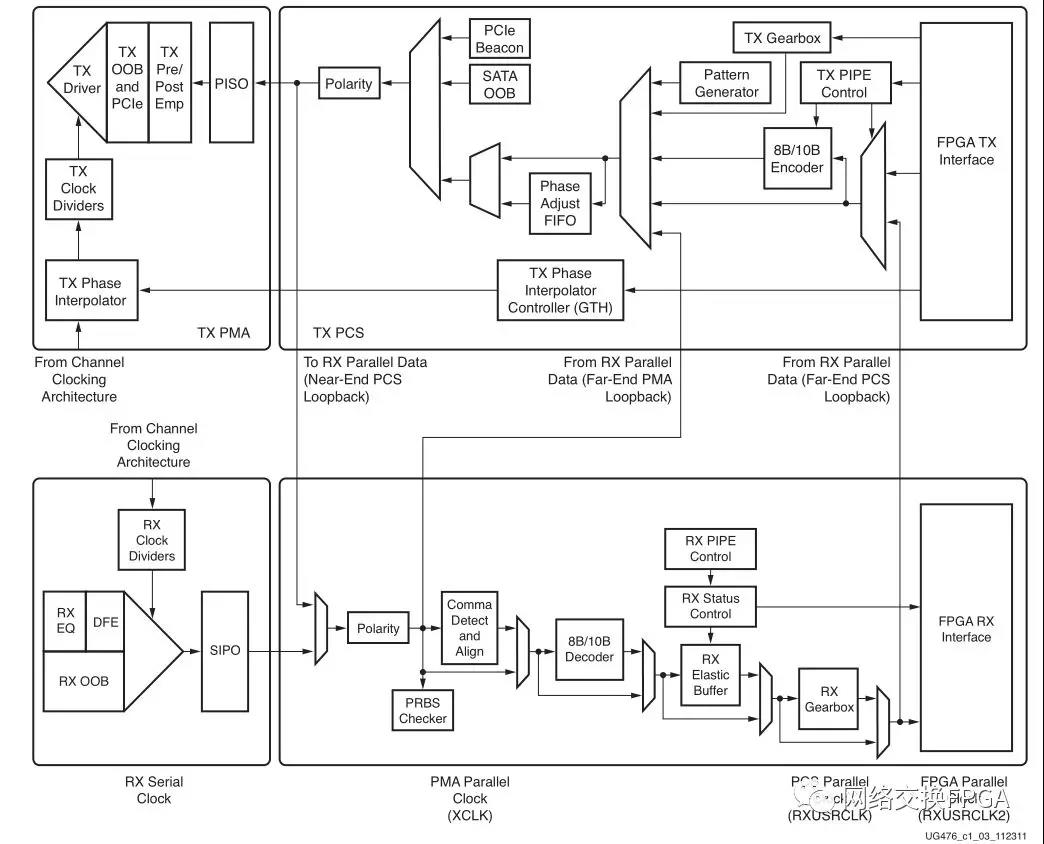
GT接口发送端处理流程:首先用户逻辑数据经过8b/10b编码后,进入一个发送缓存区,该缓冲区主要是PMA子层和PCS子层两个时钟域的时钟隔离,解决两者时钟速率匹配和相位差异的问题,最后经过高速Serdes进行并串转换。接收端和发送端过程相反,具体实现可参考ug476_7Series_Transceivers进行学习。
1.2、GT时钟使用说明
7系列FPGA通常按照bank来分,对于GTX/GTH的bank,一般称为一个Quad,原因是Xilinx的7系列FPGA随着集成度的提高,其高速串行收发器不再独占一个单独的参考时钟,而是以Quad来对串行高速收发器进行分组,四个串行高速收发器和一个COMMON(QPLL)组成一个Quad,每一个串行高速收发器称为一个Channel,其内部结构如图2所示。

从底层角度看,由于CPLL是每个Channel独有的,所以CPLL的所有接口都在Channel这个底层模块中。而QPLL是另外使用了一个叫common的底层模块。GTX中QPLL和CPLL,除了数目(每个Quad有一个QPLL四个CPLL)和归属(QPLL属于common,CPLL属于Channel)不同之外,最大的不同在于支持的最高线速率频率不同。CPLL最高只有6.xG,而QPLL可以超过10G(具体数值要根据器件的速度等级来查询DataSheet)。
对于7系列的GTX来说,每个Quad有两个外部差分参考时钟源,每个外部参考时钟的输入必须经过IBUFDS_GTE2原语之后才能使用。7系列FPGA支持使用南北相邻Quad的参考时钟作为当前Quad的参考时钟,但是一个Quad的参考时钟源不能驱动超过3个Quad上的收发器(只能驱动当前Quad和南北方相邻两个Quad)。对于一个GTX Channel来说,可以独立选择该收发器的参考时钟,可以选择QPLL,也可以选择CPLL,需要注意的是,每一个Quad上只有一个QPLL资源,重复例化会导致布线报错。
1.3、GT的主从概念
在我们使用GT 接口IP核时(Aurora和10GEthernet也适用),常提到的主核与从核的说法并不准确,这实际上只是我们在配置IP核时的一个共享逻辑的选项,如图3所示:
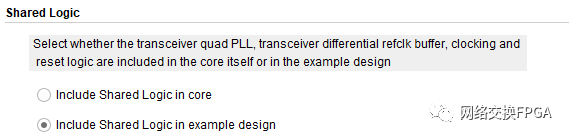
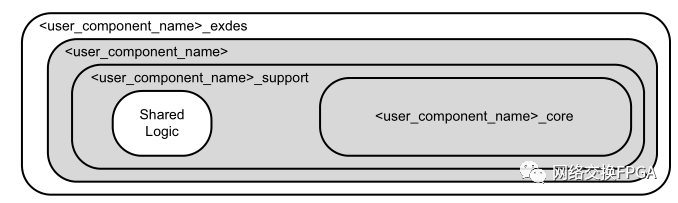
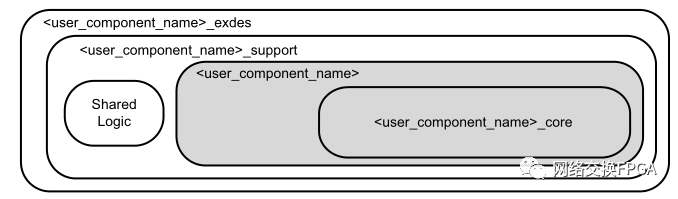
该说明中很清楚的表明,两个选项分别表示了收发器的QPLL、时钟和复位逻辑等是包含在内核本身还是示例设计(example design)中,为简单起见,我们常把共享逻辑包含在内核本身的IP称为主核,内核中不包含共享逻辑的IP称为从核,其结构如下图4和图5所示。从核与主核的区别是:我们可以在Example Design中修改共享逻辑。在实际的设计中,可以使用主核也可以使用从核,但要注意的是,若设计中使用了一个主核后,则其内部便使用了该Quad上的QPLL资源,在使用该Quad上的其他GTX接口时,不能再使用主核,也无需再给从核添加共享逻辑。
2、 Aurora接口简介
2.1、 概述
Aurora 协议是由Xilinx公司提供的一个开放、免费的链路层协议,可以用来进行点到点的串行数据传输,具有实现高性能数据传输系统的高效率和简单易用的特点。本设计中使用的Aurora 64b66b协议是一个可扩展的、轻量级的链路层协议,可以用于单路或者多路串行数据通信,单路可以实现总线位宽为64bit的数据与串行差分数据信号之间的转换。
2.2、 信号的连接
上一节有提到对于高速串行收发器,每一个Quad里仅可以使用一个QPLL(GTE2_COMMON),在我们生成一个Aurora从核并打开其example design后,这部分共享逻辑就包含在其gt_common_support模块中,该模块会产生gt_qpllclk_quad2_out、gt_qpllrefclk_quad2_out等信号供IP核使用,当我们生成一个Aurora主核时,该部分逻辑则包含在IP核内部,QPLL会作为输出信号从IP核输出。而当设计中需要2个及以上的GTX接口时,则需要将这一共享逻辑产生的信号输出给所有需要使用的IP核。以主核+从核为例,下图说明了其部分信号的连接方式:
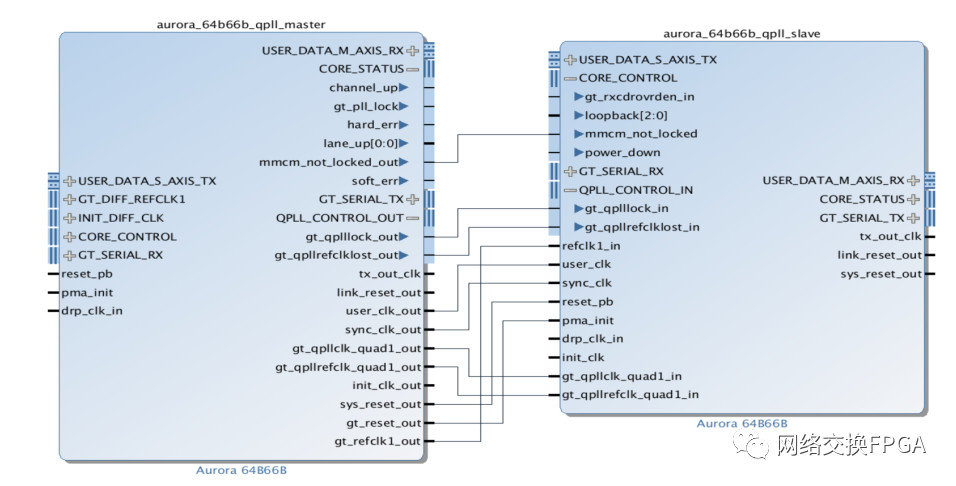
当使用两个从核时,上图连线的这些信号均在example design的共享逻辑中产生,需要人为将其输入到每一个接口IP中。
2.3、 时序逻辑
2.3.1、 链路建立
Aurora通道链路初始化完毕后会置位lane_up信号,表明接口可以接收数据;channel_up拉高时标志接口可以发送数据。一般判断这两个信号均置位时认为接口已完成初始化,可以开始进行数据传输。
2.3.2、 数据传输
Aurora接口内的数据传输格式如下图所示:
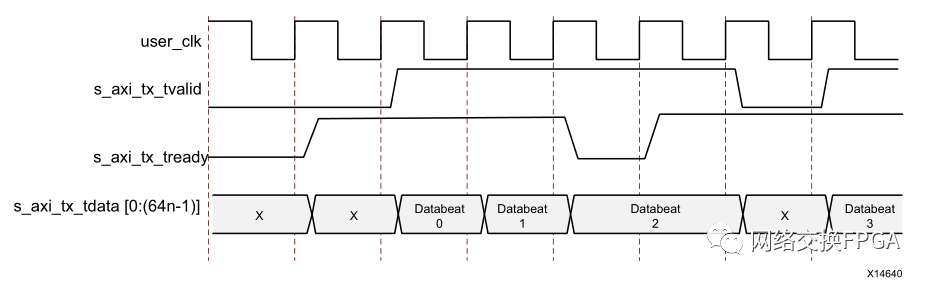
图7中,s_axi_tx_tready信号拉高时表示已准备好传输数据,该信号由链路内部的时钟补偿机制决定,不受人为控制,仅当s_axi_tx_tvalid和s_axi_tx_tready两个信号均被置为1时,才表明该时钟周期内总线数据被成功传输。
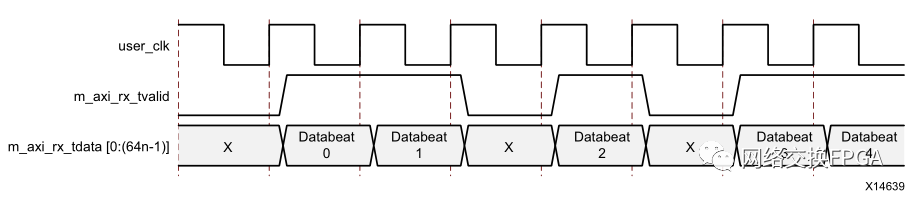
图8中,m_axi_rx_tvalid表示当前总线上的数据有效。
2.4、 接口硬件实现
SERDES是SERializer(串行器)/DESerializer(解串器)。它是一种主流的时分多路复用(TDM)、点对点(P2P)的串行通信技术。即在发送端多路低速并行信号被转换成高速串行信号,经传输媒介(连接器、铜线或光纤),最后在接收端高速串行信号重新转换成低速并行信号。这种点对点的串行通信技术充分利用传输媒体的信道容量,减少所需的传输信道和器件引脚数目,提升信号的传输速度,从而大大降低通信成本。
使用SERDES的好处除了可以最大程度上节省传输线的数量,还可以兼容板间传输和光纤传输。无论是通过何种方式连接,都需要使用XILINX的GTP/GTX高速串行传输接口。该接口的物理实现方式,是SERDERS,物理层的编码方式可以选择Aurora 8B10B或Aurora 64B66B,而应用层可以选择不同的协议,也可以不使用。
3、 10G以太网接口
可参考本公众号之前文章:10G 以太网接口的FPGA实现,你需要的都在这里了。
3.1、 概述
10G 以太网包括10GBASE-X、10GBASE-R 和 10GBASE-W。10GBASE-X 使用一种特紧凑包装,每一对发送器/接收器在 3.125Gbit/s 速度(数据流速度为 2.5Gbit/s)下工作。10GBASE-R 是一种使用 64B/66B 编码(不再使用千兆以太网中所用的 8B/10B)的串行接口,数据流为 10.000Gbit/s。10GBASE-W 是广域网接口,与 SONET OC-192 兼容,数据流为 9.585Gbit/s。本设计中使用的是Xilinx官方开源IP核10G Ethernet subsystem中10GBASE-R模式以太网光接口。
3.2、 时钟关系
对于FPGA内部的时钟布局主要分为以下4部分:
(a)输入的差分参考时钟经过一个参考钟专用缓存(IBUFDS_GTE2)变为单端时钟refclk,然后将refclk分为两路,一路接到QPLL(QuadraturephasePhase Locking Loop),另一路时钟经过一个BUFG后转变为全局时钟coreclk,继续将coreclk分为两路,一路作为10G MAC核XGMII接口的收发时钟(xgmii_rx_clk和xgmii_tx_clk),另一路用于驱动10G Ethernet PCS/PMA IP核内部用户侧的逻辑。
(b)对于QPLL输出的两路时钟qplloutclk和qplloutrefclk,主要是用于IP核内GTH收发器使用的高性能时钟,其中qplloutclk直接用于驱动GTH内发送端的串行信号,其频率为5.15625GHz。qplloutrefclk用于驱动GTH内部部分逻辑模块,频率为156.25MHz。
(c) txoutclk是由10G Ethernet PCS/PMA IP产生的一个322.26MHz的时钟,该时钟经过BUFG后分为两路,其中txusrclk用于驱动IP核内GTH的32bits总线数据,txusrclk2用于驱动IP核内PCS层部分模块。
(d)在实验室自研交换板(芯片型号xc7vx690tffg1761-2)上,25MHz的晶振产生系统时钟输入到FPGA内的PLL(Phase LockingLoop)模块,PLL模块以25MHz时钟为驱动时钟生成156.25MHz用户钟发送给10G MAC核用户侧。
3.3、 IP核配置
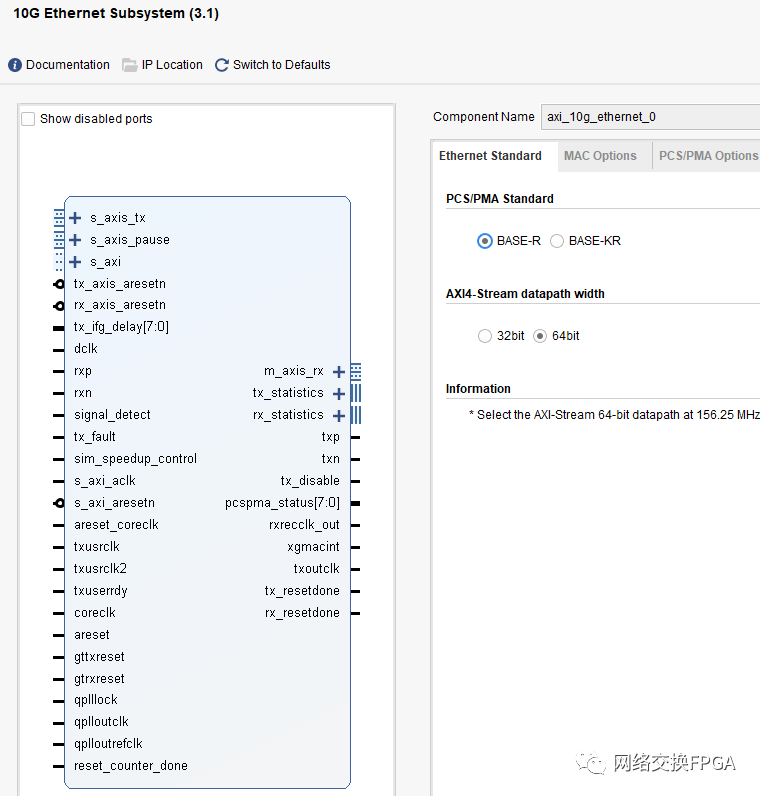
Vivado中10G以太网 IP核的配置界面如下图,该 IP 核符合 IEEE802.3-2008标准,包含 MDIO(PHY 管理接口),FCS 处理机制可配置,流量控制等功能。MAC 与 PHY 的接口使用标准 XGMII 接口,其收发数据位宽均为64bit,频率为 156.25MHz。MAC 核与用户的接口为 AXI4_STREAM,其数据位宽为64bits,工作频率也为156.25MHz。在shared logic选项卡中选择了将共享逻辑包含在example design中,也即从核模式。
共享逻辑包含一个差分输入时钟缓冲器,该缓冲器连接到GT_COMMON块,该Quad上最多可以有四个10G以太网子系统内核共享此逻辑。
使用时钟缓冲器(BUFG_GT)从收发器差分参考时钟创建coreclk / coreclk_out。coreclk / coreclk_out的频率与差分时钟源的频率相同。共享逻辑中的最终BUFG_GT来自GT_CHANNEL的TXOUTCLK,然后又连接到GT_CHANNEL,以提供收发器TX用户时钟(TXUSRCLK和TXUSERCLK2)。使用64位数据路径时,此时钟的频率为156.25 MHz;使用32位数据路径时,此时钟的频率为312.5MHz。需要注意的是,与IP核直接相连的用户数据应与coreclk对齐,即使本地的用户时钟频率与coreclk频率相同均为156.25MHz时,也可能因为非同源而导致相位偏差,因此也应采用异步FIFO进行跨时钟域处理。
3.4、 信号连接
以1个主核+2个从核为例,下图说明了其部分信号的连接方式:
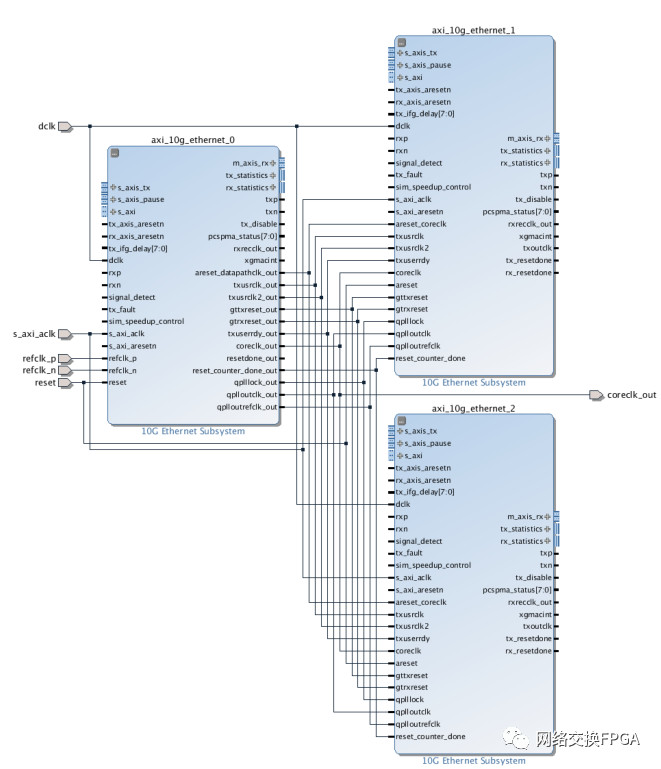
当使用两个从核时,上图连线的这些信号均在example design的共享逻辑中产生,需要人为将其输入到每一个接口IP中。
3.5、 数据传输
3.5.1、 链路建立
10G以太网通道链路初始化完毕后会置位core_ready信号,表明接口接口已完成初始化,可以开始进行数据传输。
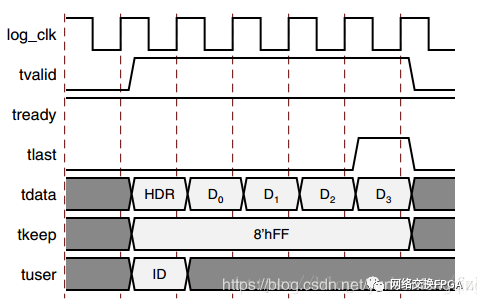
3.5.2、 数据格式
10G以太网接口用户侧采用的AXI-Stream总线数据格式如下图所示:
3.6、 接口硬件实现
在远距离连接的场景中,铜导线已经不能满足如此长距离,大数据量的通信,因此必须要采用光纤通信的方案。实现该方案需要使用光模块。
光模块是进行光电和电光转换的光电子器件。光模块的发送端把电信号转换为光信号,接收端把光信号转换为电信号。光模块按照封装形式分类,常见的有SFP,SFP+,XFP等。光模块的接口是完全兼容XILINX的GTP/GTX IO,接口电路如图所示:
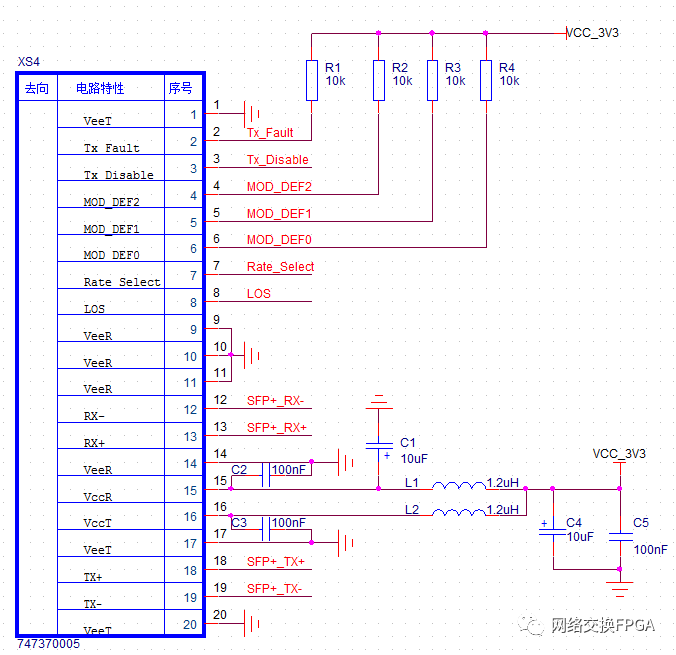
光模块的种类有很多,下面只针对项目中常见的三种光模块作介绍。
1)SFP光模块
SFP光模块是一种小型可插拔光模块,目前最高速率可达10.3G(市面上基本为1.25G),通常与LC跳线连接。SFP光模块主要由激光器构成。SFP分类可分为速率分类、波长分类、模式分类。SFP光模块又包含了百兆SFP、千兆SFP、BIDI SFP、CWDM SFP和DWDM SFP。
2)SFP+光模块
SFP+光模块的外形和SFP光模块是一样的,传输速率可以达到10G,常用于中短距离传输。SFP+光模块是一种可热插拔的,独立于通信协议的光学收发器。
3)XFP光模块
XFP光模块是一种可热插拔的,独立于通信协议的光学收发器。速率同样可以达到10G,但是体积比SFP/SFP+光模块要大。
通过比对分析,SFP+光模块具有比XFP更紧凑的外形尺寸,比SFP更高的速率,因此在远距离光纤传输中是一种较为优秀的方案。
本设计中10G以太网接口在硬件上采用SFP+光模块实现光电转换。
三、帧结构分析
1、 以太网帧结构
该部分内容也可参看本公众号之前文章:你见过物理层的以太网帧长什么样子吗?
目前主要有两种格式的以太网帧:Ethernet II(DIX 2.0)和IEEE 802.3。本设计使用Ethernet II帧结构,其帧格式如图13所示:

各字段具体说明如下:
⑴ 前导码(Preamble):由0、1间隔代码组成,用来通知目标站作好接收准备。
⑵ 目标地址和源地址(Destination Address & Source Address):表示发送和接收帧的工作站的地址,各占据6个字节。其中,目标地址可以是单址,也可以是多点传送或广播地址。
⑶ 类型(Type)或长度(Length):这两个字节在Ethernet II帧中表示类型(Type),指定接收数据的高层协议类型。
⑷ 数据(Data):在经过物理层和逻辑链路层的处理之后,包含在帧中的数据将被传递给在类型段中指定的高层协议。该数据段的长度最小应当不低于46个字节,最大应不超过1500字节。如果数据段长度过小,那么将会在数据段后自动填充(Trailer)字符。相反,如果数据段长度过大,那么将会把数据段分段后传输。
⑸ 帧校验序列(FSC):包含长度为4个字节的循环冗余校验值(CRC),由发送设备计算产生,在接收方被重新计算以确定帧在传送过程中是否被损坏。
2、Spirent Testcenter业务流格式
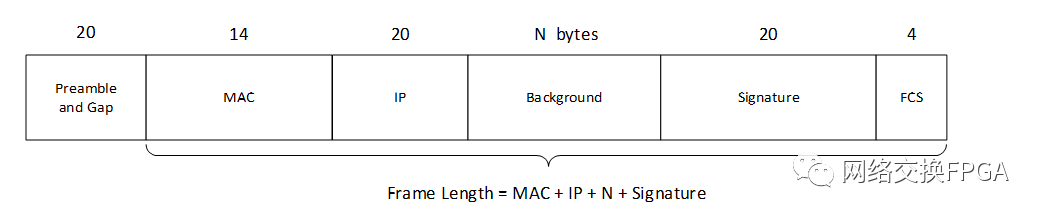
当使用Testcenter配置以太网数据帧时,Testcenter会在以太网帧的数据字段自动添加20个字节的开销,即上图中的Signature字段,该字段的各部分功能如下:
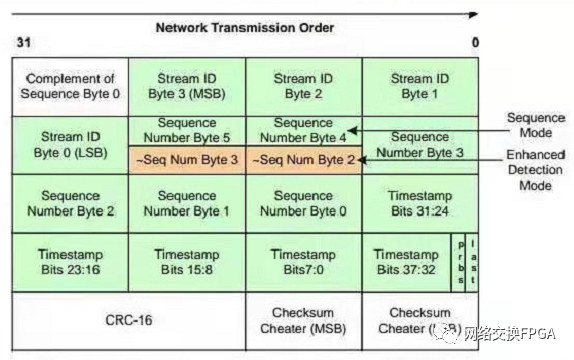
该字段包含32bit(4个字节)的流ID,支持40亿个测试流。
该字段具有10纳秒的时间戳分辨率
当Spirent Testcenter在有效负载中插入PRBS23码型时,PRBS位置1
Last位会告诉接收方时间戳所在字节
该字段具有一个内置的UDP / TCP Checksum Cheater字段(用于在有效载荷中放置修饰符时使用)
由于该Signature字段是SpirentTestcenter业务流的唯一标识,Testcenter通过识别接收到的数据流的Signature字段来计算链路时延并判断是否有丢帧的情况,此外,该字段在Testcenter软件中不对用户可见,也即我们无法人为的去配置这个字段,因此建议在处理数据帧时,不要删改该字段信息。当然,也可以选择让Testcenter不添加这一字段,但是这样Testcenter在接收到以太网帧之后无法与已发送的数据帧进行比较。本设计选择的方案是默认在Testcenter业务流后自动添加Signature字段。
3、 自定义帧格式
本实验在标准以太网EthernetII帧格式的基础上重新定义了系统内部帧格式,如下图:
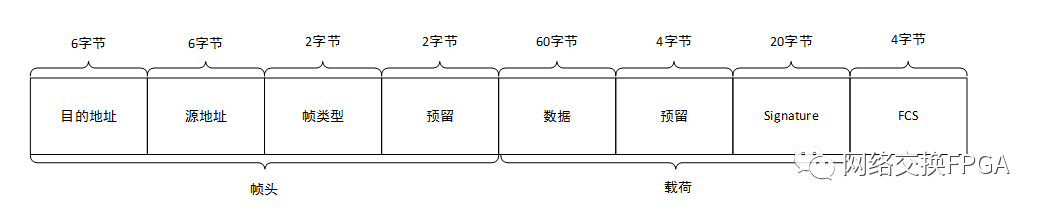
上图中目的地址、源地址、帧类型和FCS字段均保留了EthernetII帧结构,而为了逻辑简单起见,将数据字段重新拆分成四个字段,其中预留字段仅起占位功能,Signature字段为Testcenter自动填充的开销字段。实验中真正使用的也就是载荷部分的84字节。
四、数据处理流程
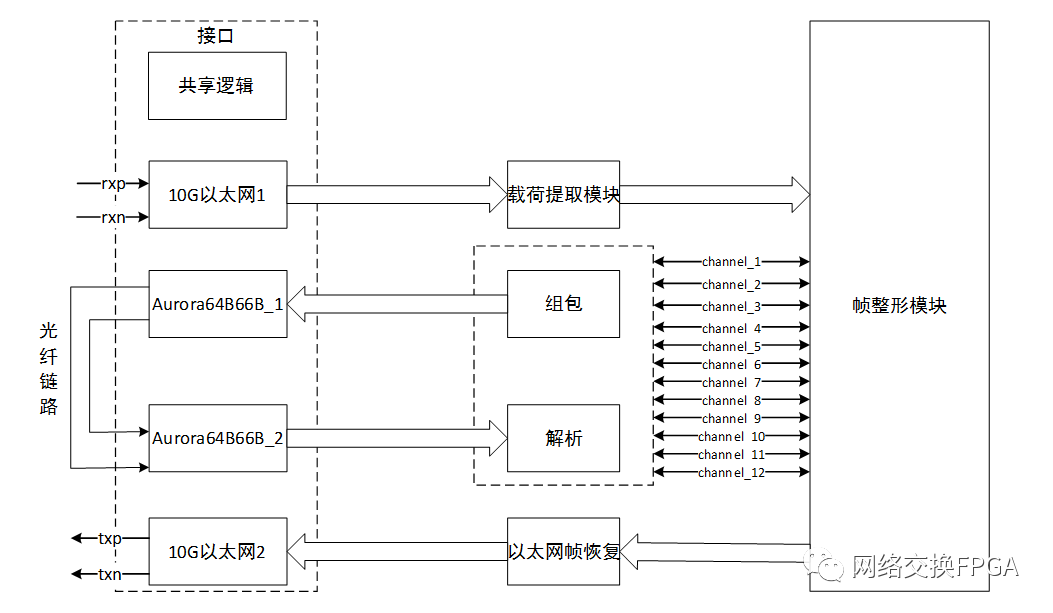
1、 实现方案
1.1整体架构
10G以太网接口接收来自Testcenter测试设备发送过来的以太网帧,提取出关键字段将其拆分成并行的12路通道数据,与clk时钟同步,然后将这些数据进行组包,N个clk内的数据组合成一帧,使用aurora64B66B将数据一帧一帧地发送出去,接收机对收到的帧数据进行解析,并还原成与内部clk同步的12路通道数据,在将12路数据合并成以太网帧格式,通过10G以太网接口发送回Testcenter。实现框图如下:
1.2、数据流程
根据上述设计架构,本设计的数据流程如下图:

五、主要模块仿真RTL级验证
1、 10G以太网接口功能验证
在10G以太网接口1发送端写入64位固定帧,接口将其转换成差分信号输出,在差分端打环,使接口1发送出的差分信号进入接口2的接收端,将接收端恢复出的并行数据与数据源数据进行比较。仿真结果如下图:
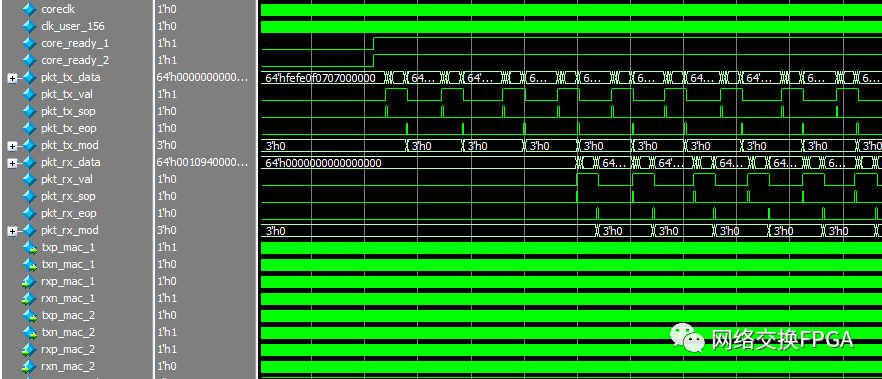
在core_ready信号拉高后向接口1发送端pkt_tx_*写入数据,将接口1与接口2的差分端相连,监测接口2接收端pkt_rx_*恢复出的以太网帧。
2、 Aurora64B66B接口功能验证
在Aurora64B66B接口1发送端写入64位固定帧,接口将其转换成差分信号输出,在差分端打环,使接口1发送出的差分信号进入接口2的接收端,将接收端恢复出的并行数据与数据源数据进行比较。仿真结果如下图:

六、板级验证
1、 验证环境


实验选取实验室自研交换板(芯片型号xc7vx690tffg1761-2),该交换板具有6个GTH光口,本设计选取4个光口进行测试,左起1口、4口为10G以太网接口,通过光纤与Testcenter相连,如图32所示。2口、3口为Aurora64B66B接口,通过光纤实现外环连接。
2、 测试流配置
在Testcenter配套软件上配置业务流时,为直观的验证本设计功能,为以太网帧配置payload,即添加custom header,如图33所示:
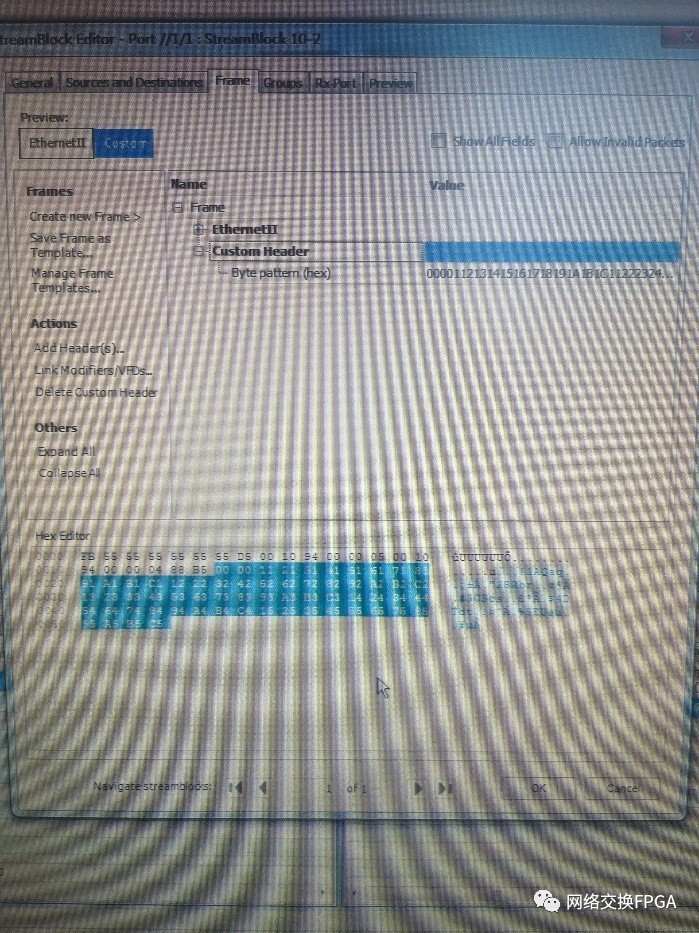
3、 验证结果
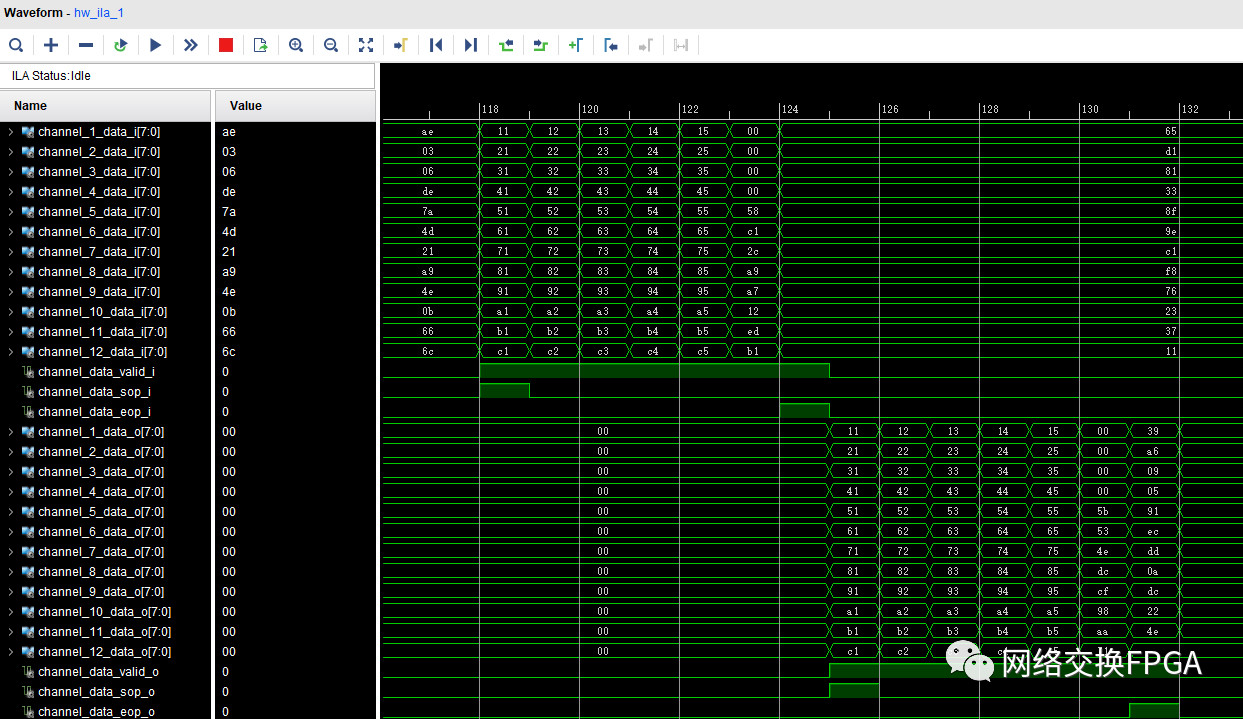
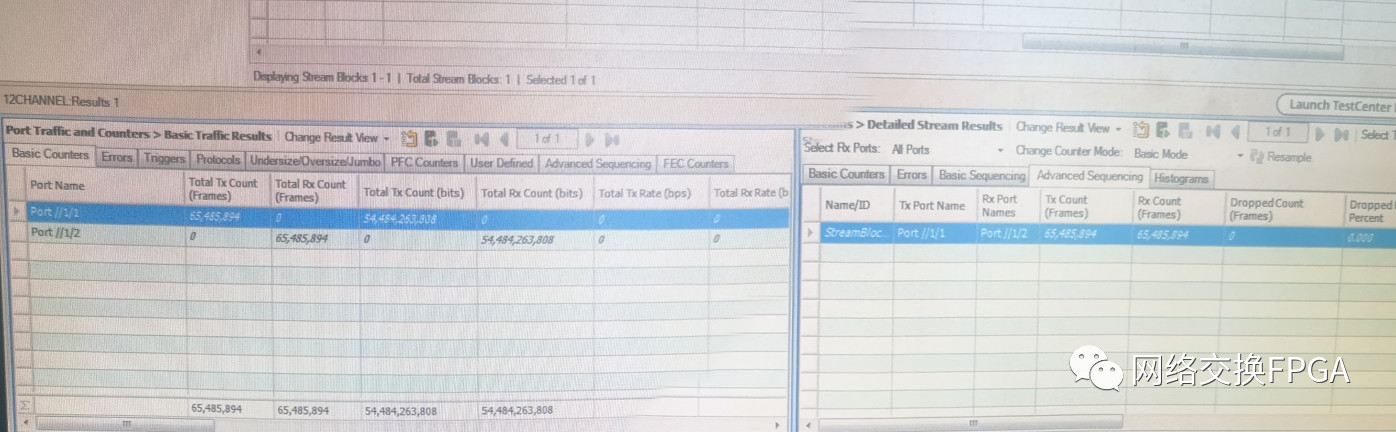
通过Xilinx ila抓取部分信号,从图34可以看到本设计可以成功的提取出以太网帧的载荷字段,并从中解析出并行的12路通道数据,前60字节与6.2中配置字段相同,本设计功能实现良好。图35中对Testcenter接收到的数据帧进行统计并与已发送的数据帧进行比较,表明本设计未出现丢帧、错帧情况。
七、附录
下面提供实现本设计的另一种思路:
在前几章提及GT Quad中QPLL资源的问题,即一个Quad上仅能够使用一个QPLL,因此本设计使用了四个GTH接口共同使用一个共享逻辑,其QPLL时钟信号需要驱动2个10G以太网接口和2个Aurora64B66B接口。对初学者来说,梳理清楚GT时钟并使用QPLL是具有一定困难的,最简单的方法是,将4个接口分别放置在两个Quad上,即每两个GT接口共享一个QPLL资源,这样可以直接使用Xilinx官方文档中的1主带1从的模式,尽可能的简化了代码并大大减少调试中的困难。
本实验选择的交换板上带有标准FMC扩展口,其上具有丰富的GT资源,下图展示了FMC扩展板与交换板的连接,以及通过同轴电缆将扩展板上的差分端口相连实现外环。





本文转自:网络交换FPGA





