作者:Quenton Hall,赛灵思公司工业、视觉、医疗及科学市场 AI 系统架构师
来源: https://forums.xilinx.com/t5/AI-and-Machine-Learning-Blog/AI-s-Energy-Pr...
在 "人工智能引发能源问题,我们该怎么办 (一)"中,我们简要介绍了更高层次的问题,这些问题为优化加速器的需求奠定了基础。作为一个尖锐的问题提醒,现在让我们通过一个非常简单的图像分类算法,来看一看与之相关联的计算成本与功耗。
利用 Mark Horowitz 提供的数据点,我们可以考虑图像分类器在不同空间限制下的相对功耗。虽然您会注意到 Mark 的能耗估计是针对 45nm 节点的,但业界专家建议,这些数据点将继续按当前的半导体工艺尺寸进行调整。也就是说,无论工艺尺寸是 45nm 还是 16nm,与 FP32 运算相比,INT8 运算的能量成本仍然低一个数量级。
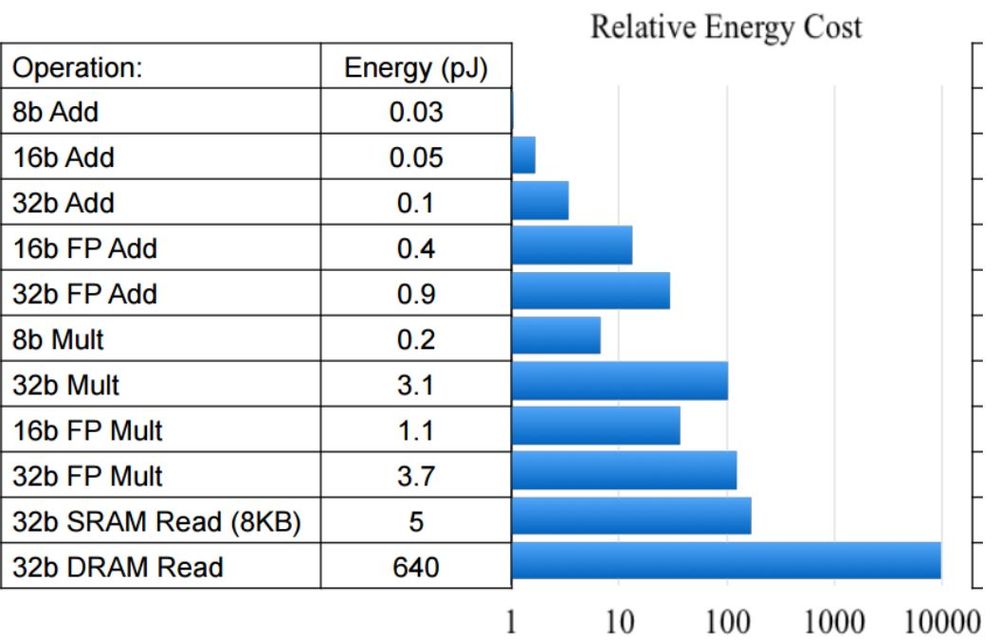
数据来源:Bill Dally(斯坦福),Cadence 嵌入式神经网络峰会,2017 年 2 月 1 日
功耗可按以下方式进行计算:
功耗 = 能量(J)/运算*运算/s
从这个等式中我们可以看出,只有两种方法能够降低功耗:要么减少执行特定运算所需的功耗,要么减少运算的次数,或者一起减少。
对于我们的图像分类器,我们将选择ResNet50作为一个目标。ResNet 提供了近乎最先进的图像分类性能,同时与众多具有类似性能的可比网络相比,它所需的参数(权重)更少,这便是它的另一大优势。
为了部署 ResNet50,我们每次推断需要大约 77 亿运算的算力。这意味着,对于每一幅我们想要分类的图像,我们将产生 7.7 * 10E9 的“计算成本”。
现在,让我们考虑一个相对高容量的推断应用,在该应用中,我们可能希望每秒对 1000 幅图像进行分类。坚持沿用 Mark 的 45nm 能耗估算,我们得出以下结论:
功耗 = 4pJ + 0.4pJ/运算*7.7B运算/图像 * 1000图像/s
= 33.88W
作为创新的第一维度,我们可以将网络从 FP32 量化到 8 位整数运算。这将功耗降低了一个数量级以上。虽然在训练期间 FP32 的精度有利于反向传输,但它在像素数据的推断时间几乎没有创造价值。大量研究和论文已经表明,在众多应用中,可以分析每一层的权重分布并对该分布进行量化,同时将预量化的预测精度保持在非常合理的范围内。
此外,量化研究还表明,8 位整数值对于像素数据来说是很好的“通用”解决方案,并且对于典型网络的许多内层,可以将其量化到 3-4 位,而在预测精度上损失最小。由 Michaela Blott 领导的赛灵思研究实验室团队多年来一直致力于二进制神经网络 (BNN) 的研究与部署,并取得了一些令人瞩目的成果。(如需了解更多信息,请查看 FINN 和 PYNQ)
如今,我们与DNNDK的重点是将网络推断量化至 INT8。现代赛灵思 FPGA 中的单个 DSP 片可以在单个时钟周期内计算两个 8 位乘法运算,这并非巧合。在 16nm UltraScale+ MPSoC 器件系列中,我们拥有超过 15 种不同的器件变型,从数百个 DSP 片扩展到数千个 DSP 片,同时保持应用和/OS 兼容性。16nm DSP 片的最大 fCLK 峰值为 891MHz。因此,中型 MPSoC 器件是功能强大的计算加速器。
现在,让我们考虑一下从 FP32 迁移到 INT8 的数学含义:
功耗 = 0.2pJ+0.03pJ/运算*7.7B运算/图像*1000图像/s
= 1.771W
Mark 在演讲中,提出了一个解决计算效率问题的方法,那就是使用专门构建的专用加速器。他的观点适用于机器学习推断。
上述分析没有考虑到的是,我们还将看到 FP32 的外部 DDR 流量至少减少四倍。正如您可能预料到的那样,与外部存储器访问相关的功耗成本比内部存储器高得多,这也是事实。如果我们简单地利用 Mark 的数据点,我们会发现访问 DRAM 的能量成本大约是 1.3-2.6nJ,而访问 L1 存储器的能量成本可能是 10-100pJ。看起来,与访问内部存储器(如赛灵思 SoC 中发现的 BlockRAM 和 UltraRAM)的能量成本相比,外部 DRAM 访问的能量成本至少高出一个数量级。
除了量化所提供的优势以外,我们还可以使用网络剪枝技术来减少推断所需的计算工作负载。使用赛灵思Vitis AI 优化器工具,可以将在 ILSCVR2012(ImageNet 1000 类)上训练的图像分类模型的计算工作负载减少 30-40%,精度损失不到 1%。再者,如果我们减少预测类的数量,我们可以进一步增加这些性能提升。现实情况是,大多数现实中的图像分类网络都是在有限数量的类别上进行训练的,这使得超出这种水印的剪枝成为可能。作为参考,我们其中一个经过剪枝的 VGG-SSD 实现方案在四个类别上进行训练,需要 17 个 GOP(与原始网络需要 117 个 GOP 相比),在精度上没有损失!谁说 VGG 没有内存效率?
然而,如果我们简单地假设我们在 ILSCVR2012 上训练我们的分类器,我们发现我们通常可以通过剪枝减少大约 30% 的计算工作负载。考虑到这一点,我们得出以下结论:
功耗 = 0.2pJ+0.03pJ/运算*7.7B运算/图像0.7*1000图像/s
= 1.2397W
将此值与 FP32 推断的原始估计值 33.88W 进行比较。
虽然这种分析没有考虑到多种变量(混合因素),但显然存在一个重要的优化机会。因此,当我们继续寻找遥遥无期的“解决计算饱和的灵丹妙药”时,考虑一下吴恩达断言“AI 是新电能”的背景。我认为他并不是在建议 AI 需要更多的电能,只是想表明 AI 具有极高的价值和巨大的影响力。所以,让我们对 ML 推断保持冷静的头脑。对待机器学习推断应保持冷静思考,既不必贸然跟风,也无需针对高性能推断设计采用液态冷却散热。
在本文的第三篇中,我们还将就专门构建的“高效”神经网络模型的使用,以及如何在赛灵思应用中利用它们来实现更大的效率增益进行讨论。在此之前,请参阅DNNDK SDK 用户指南中的第 7 章,以便您更好地了解自适应硬件(位于边缘和更远位置)可能实现的推断性能水平。
未完待续
文章来源: 赛灵思中文社区论坛