跳转到主要内容
FPGA 开发圈
Toggle navigation
新闻
视频
技术文章
博客
下载中心
活动
登录
注册
掌握多轴机器人技术:详细步骤指南
智多晶高精度PWM控制方案
五项功能可提升边缘端嵌入式 AI 性能
Verilog代码转VHDL代码经验总结
Verilog语言和VHDL语言是两种不同的硬件描述语言,但并非所有人都同时精通两种语言,所以在某些时候,需要把Verilog代码转换为VHDL代码。本文以通用的XHDL工具为例对Verilog转换到VHDL过程中存在的问题进行了总结
2019-07-17 |
Verilog
,
VHDL
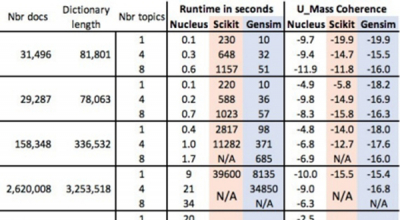
SumUp Analytics Nucleus 平台
SumUp Analytics 的 Nucleus 平台是一个提供 Xilinx FPGA 支持的实时文本分析 SaaS 算法,用于从非结构化文本中识别、提取和分析重要信息。该平台在采用 Alveo™ U200 加速器卡的本地设备或 AWS EC2 F1 实例上无缝工作。Nucleus 不仅包括一个运行在 Xilinx FPGA 上的 Python/SDAccel 混合库,用于核心分析,...
阅读详情
2019-07-17 |
Nucleus
,
Alveo-U200
Spartan-7 SP701 FPGA 评估套件
SP701 评估套件配备业界最佳性能功耗比 Spartan®-7 FPGA,适用于需要传感器融合的设计,如工业网络、嵌入式视觉和汽车等应用。SP701 通过 Pmods 和 FMC 连接器提供高 I/O 可用性和 I/O 扩展,使其成为 Spartan-7 FPGA 用户最大的 IP 开发平台。所包含的 XC7S100 FPGA 是 Spartan-7 系列中密度最大的器件。XC7S100 拥有...
阅读详情
2019-07-16 |
Spartan-7
,
SP701
【视频】通过 XIlinx SoC 将 DNNDK 用于自定义应用
使用 Xilinx 深度学习处理器(DPU)IP 构建自定义系统,使用面向 Xilinx SoC 的 DNNDK 优化经过训练的推断模型。
2019-07-16 |
DNNDK
,
深度学习
Xilinx 计算库
Xilinx 计算库提供加速数学、统计、线性代数、金融函数和预构建定价模型,帮助开发人员快速构建各种加速应用。代码是开源的,可根据需要修改。
2019-07-16 |
Xilinx
,
Xilinx计算库
图像处理二:HDMI显示(二)
本篇完成对HDMI显示代码的UVM仿真,梳理一下在windows-modelsim工具下UVM仿真环境的建立,调试以及遇到的问题。仿真的架构在上一篇已经做了简要介绍,这部分做重点讲解
2019-07-16 |
图像处理
,
HDMI显示
UltraScale+ FPGA Gen3 Integrated Block for PCI Express (Vivado 2019.1) 集成调试特性及使用指南
本文档描述了 Vivado 2019.1 中 PCI Express 内核的 UltraScale+ FPGA Gen3 集成块中集成的易用性特性。这些特性将在截图中详细介绍,以帮助用户更轻松理解其实现方案和用途。
2019-07-15 |
Vivado 2019.1
介绍一篇可以动态编辑Xilinx FPGA内LUT内容的深度好文!
文章阐述了Xilinx FPGA可编程的本质,逆向分析破解了FPGA编程的bit流文件,并将其与FPGA内部电路相对应,对于深度理解动态可编程及FPGA电路结构具有重要的指导价值,LUT动态可编程使得FPGA内部的资源使用起来更灵活,你可以把LUT当成BRAM使用,也可以随时改变若干个LUT组成电路完成的硬件功能
2019-07-15 |
Xilinx FPGA
Xilinx 7系列FPGA之MGT简介
本篇作为xilinx 7系列FPGA简介篇的最后一篇,咱们来介绍MGT(Multi-gigabittransceiver)
2019-07-15 |
7系列FPGA
,
MGT
,
高速串行收发器
在DNN中FPGA做了什么?
深度神经网络(deep nearal network)是机器学习发展20年来取得的最大突破,比如在语音识别方面,相比于传统方法,其将错误率降低了30%;而在2011年的图片识别竞赛上,将错误率从26%降低到3.5%,这些使得处于发展低谷的人工智能突然热门起来,从学术界扩展到工业界,甚至在google的alpha go击败了顶级围棋大师李世石后,人工智能成为全民讨论的热门,...
阅读详情
2019-07-15 |
DNN
,
FPGA技术
R3VLab首席技术官Nigel:做PoC硬件挖矿和分布式存储领域的佼佼者
自比特币诞生之后,PoW挖矿作为最主流的共识机制已经运行了十年有余,而近年来由于挖矿造成的巨大能源消耗、算力逐渐集中于几大矿池而趋向中心化,以及挖矿设备相对较高的准入门槛使得越来越多的人转向新的共识机制,如PoS、DPoS、PoC等等
2019-07-15 |
R3VLab
,
挖矿
,
分布式存储
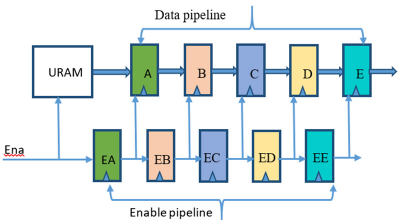
通过在 Vivado Synthesis 中使 URAM 矩阵自动流水线化来实现最佳时序性能
UltraRAM 原语(也称为 URAM)可在 Xilinx UltraScale +™ 架构中使用,而且可用来高效地实现大容量深存储器。URAM 原语具有实现高速内存访问所需的可配置流水线属性和专用级联连接。 流水线阶段和级联连接是使用原语上的属性来配置的。 本篇博文描述的是通过将 URAM 矩阵配置为使用流水线寄存器来实现最佳时序性能的方法。
2019-07-12 |
URAM
InAccel 的加速机器学习解决方案
使用逻辑回归、K 均值和交替最小二乘法加速您的 Apache Spark 应用。 AML 是 InAccel 的加速机器学习库。旨在维护其它开源框架(如 Apache Spark)简单易用的实用接口,同时加速机器学习模型的训练环节。现在 AML 拥有所有所需的库,可训练您的逻辑回归和 Kmeans 模型
2019-07-12 |
InAccel
,
机器学习
Xilinx的COE文件格式有区别
Xilinx的FIR的COE文件应该是这样的: fileID = fopen('fir_h.coe','w'); fprintf(fileID,'%s\n%s\n','radix=10;','coefdata='); fprintf(fileID,'%.0f,\n',h); fclose(fileID); radix=10; coefdata= -809...
阅读详情
2019-07-12 |
Xilinx
,
COE文件
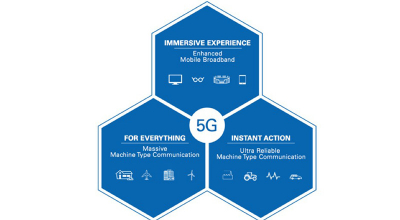
毫米波(mmWave):频段之战
无线设备和其处理的数据量每年都呈指数递增(53% 复合年增长率。随着这些设备产生并处理的数据量越来越多,连接这些设备的无线通信基础设施也必须持续发展才能满足需求。如图 1 所示,4G 网络频谱效率的提高已经不足以提供 3GPP[2] 定义的三大高级 5G 用例所需数据速率...
阅读详情
2019-07-12 |
毫米波
,
mmWave
,
频段
,
5G
第一页
前一页
…
311
312
313
…
下一页
末页