8月 29 日至 9 月 2 日,可编程逻辑领域的顶级会议之一——“现场可编程逻辑与应用国际会议”(简称FPL) 将在英国贝尔法斯特举行,AMD北京 AI 研发团队的两篇论文成功入选本届会议,分别为《XVDPU:基于 Versal 平台 AI 引擎的高性能 CNN 加速器设计》和《A-U3D: 基于 Versal 平台统一 2D/3D CNN 加速器设计以及针对视差估计应用的优化》。FPL 会议注重硬件架构设计和硬件工具领域的研究。此次 AMD AI 研发团队入选的两篇论文侧重基于 Versal 异构计算平台的 AI 处理器架构设计,充分发挥 Versal 平台的算力和灵活性优势。
今年 CVPR 会议上,AMD AI 研发团队的两篇论文成功入选。在同期举办的计算机图像恢复领域最具影响力的全球赛事 NTIRE 2022 挑战赛上,团队获得高效超分辨率(Efficient Super-Resolution)精度赛道第一的佳绩,相关技术报告也被 CVPR Workshop 接收。
“数据、算法和算力是 AI 的三大基石。AMD AI研发团队在顶级学术会议上取得的一系列成绩,不仅展现了团队在算法和算力提升方面的研究成果,也源于团队在创新研究和客户需求双重驱动下的不懈探索,通过前沿研发更好地提升产品核心竞争力,从而助力客户打造更卓越的解决方案。”——单羿博士,AMD公司副总裁、AI研发团队负责人


论文第一作者:贾希杰,AMD高级开发经理
当前,卷积神经网络广泛应用于计算机视觉领域。更高精度和分辨率的需求引入了更复杂的神经网络,算力和数据读写 I/O 因而日益成为瓶颈。AMD 7nm Versal ACAP 具备 AI 引擎核(AIE 核),与传统 FPGA 解决方案相比,能够以 50% 的能耗提供8倍的算力。
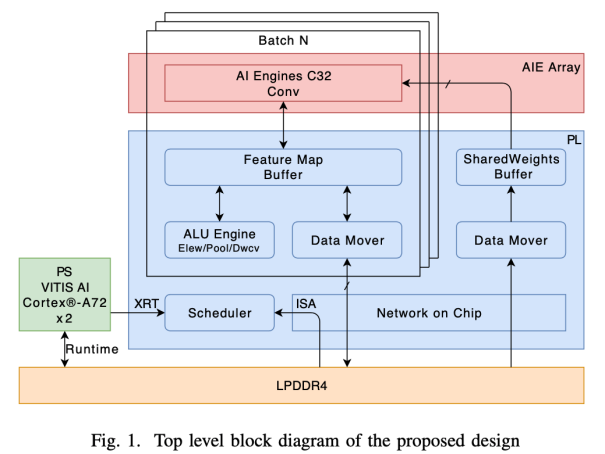
上图展示了论文中 XVDPU 加速器的架构设计,它具有以下特征:
1. 基于 Versal 平台芯片,卷积运算由片内 AIE 核执行,支持 int8 量化精度;
2. 支持 AIE 核数从 16 到 320 之间按 16 整数倍灵活配置,320 个 AIE 核可提供 109.2 TOPs 的峰值算力;
3. 采用一系列技术优化手段解决I/O瓶颈,包括多 batch 设计(MB)、共享权重(SHRWGT)、片上存储中间层数据(FMS)和单指令权重加载(LLW)技术等,力求增加数据复用率并减少带宽需求;
4. 为平衡计算资源、扩展新功能和提升整体性能,设计了通用计算单元 ALU 模块来执行神经网络中的非卷积计算,包括DepthWise Conv、Pooling、ElementWise 和 Non-linear 等功能;
5. 支持 100 余个 CNN 模型,加速器在 VCK190 板卡上进行了多个配置的实现,其中,仅使用 96 核配置(C32B3,Peak:32.76TOPs)运行 resnet50 帧率 1653FPS,9.8 倍于ZCU102 上的 168.5FPS。仅使用 256 核配置(C32B8, Peak:87.36TOPs)更充分地利用了 AIE 算力,运行帧率达 4050FPS。
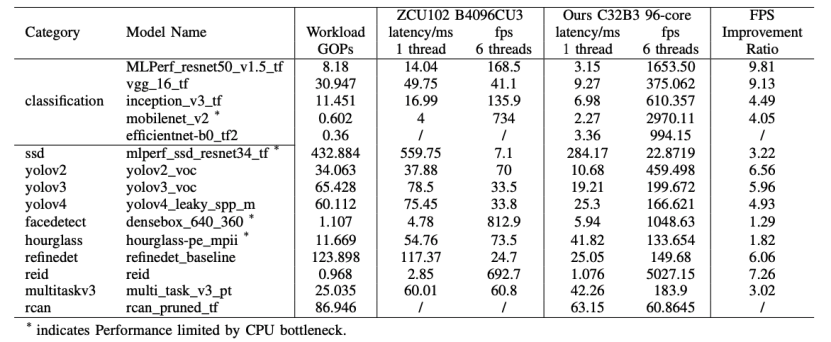
实验表明,仅使用 96个AIE 核的配置,XVDPU 具有 9.8 倍于 ZCU102 ZU9 MPSoC 的计算能力和更高的计算效率,对于非 I/O 瓶颈的网络,如 MLPerf_resnet50_v1.5_tf 和 vgg_16_tf,可以获得 9 倍多的 FPS 性能,限于板卡的 DDR 带宽(68.3GB/s),所支持的网络中可以获得 1 倍多到 9 倍多的 FPS 性能。
XVDPU 是一个“AI 引擎 + PL 逻辑 + PS CPU”的混合异构计算系统:AI 引擎具有强大的并行计算能力,应用于推理计算可以获得高能效比;PL 逻辑的在线可编程特性提供了灵活性,可以根据网络模型的变化进行升级,支持最新的网络模型;借助 PS ARM核中的Linux系统,灵活支持应用软件。异构计算系统各部分发挥各自优势,合力构建了高性能CNN加速器。
得益于强大的计算性能和计算效率、新型网络模型的广泛支持,XVDPU 上已经成功部署超过 100 个CNN模型,从低时延数据中心到高阶自动驾驶、再到复杂机器人系统等广泛的嵌入式系统,都能够从中受益。


论文第一作者:张天宇,AMD高级工程师
视差估计是一项基本的计算机视觉任务,它在给定一对校正立体图像的情况下预测每个像素的视差,在自动驾驶、机器人等领域具有广泛的应用。最近基于 CNN 的方法将 3D 卷积和视差回归用于视差估计。PSMNet 是流行的基于 3D CNN 的解决方案之一,具有良好的保真度结果,但部署网络消耗算力大。在这项工作中,团队以 PSMNet 为例,旨在为嵌入式设备上的一般视差估计任务提供参考解决方案。论文中介绍的加速器架构设计如下图所示。
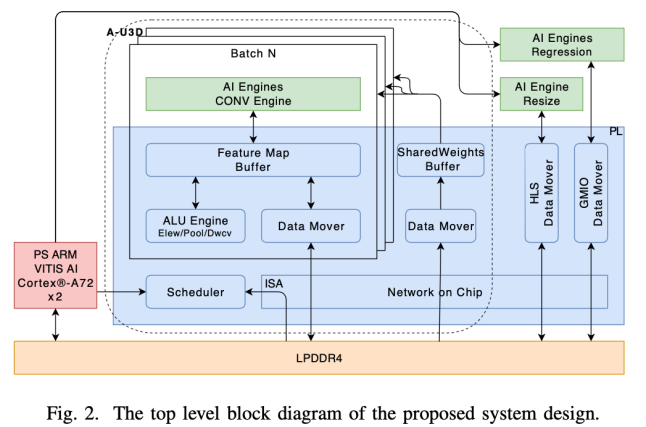
本论文研究的独特价值在于以下3方面:
1.b针对 PSMNet 模型的大算力需求。团队进行了一系列优化,优化前其算力为 2.16T FLOPs。通过对模型进行修剪和量化,将其算力需求压缩为 696GOPs,量化精度为 8bit,以降低计算复杂度和内存占用。
2. 针对 PSMNet 的复杂模型结构。将模型中的 3D 标准/转置卷积分别整合统一为 2D 标准卷积,计算单元可以在相同模式下执行 2D 和 3D 卷积操作,而无需额外的结构。设计了基于 Versal 平台的混合计算架构,在 CPU(ARM)的调度下,AIE 核、PL中的DSP、PS的 ARM 核可以并行计算,以应对各种计算需求。
3. 提出了基于A-U3D的视差估计解决方案,在 VCK190 板卡上仅使用 96 个 AIE 核,系统运行 8bit 剪枝 PSMNet 网络的时延为 0.289s,E2E 性能可以达到 10.1FPS。
与不同平台相比,团队的工作实现了更高的能量效率、0.289s的延迟和10.1FPS的帧率。在轻量级工作负载模型中,该解决方案展示了超过 10,000 GOP/s E2E 吞吐量。因此,这种解决方案具备更高的实用性,非常适合应用于自动驾驶、机器人和其它机器视觉相关领域。






