ElectroKnox 借助赛灵思 Zynq® 平台将软件定义汽车变成现实
judy 在 周五, 07/23/2021 - 10:11 提交
ElectroKnox 需要为前沿汽车应用、服务和安全建立通用且强大的基础。该公司的 SGW1000 汽车智能网关解决方案是一种基于赛灵思 Zynq UltraScale+ MPSoC 平台的软硬件统一平台解决方案。该方案支持 OEM 厂商快速在软件中开发功能,并缩短上市进程,让“软件定义汽车”的理念进一步贴近现实。
Zynq® UltraScale+™ MPSoC(多处理器系统芯片)是赛灵思(Xilinx)推出的一款集成了处理器系统和可编程逻辑的器件。这一系列芯片采用 UltraScale+ 架构,结合 ARM 处理器和可编程逻辑,为嵌入式系统提供了灵活性和高性能。
Zynq UltraScale+ MPSoC 适用于嵌入式系统设计,特别是对于需要高度定制和硬件加速的应用。它为设计人员提供了处理器和 FPGA 的集成解决方案,以满足各种复杂系统的需求。
ElectroKnox 需要为前沿汽车应用、服务和安全建立通用且强大的基础。该公司的 SGW1000 汽车智能网关解决方案是一种基于赛灵思 Zynq UltraScale+ MPSoC 平台的软硬件统一平台解决方案。该方案支持 OEM 厂商快速在软件中开发功能,并缩短上市进程,让“软件定义汽车”的理念进一步贴近现实。

“软硬兼长”是京信与赛灵思合作的基础,也是更好赋能 Open RAN 的一大关键。自2007年初以来,京信随即开始采用赛灵思芯片及解决方案,并随其演进步伐持续开发高质量无线电产品及系统。赛灵思 Artix 7 系列 FPGA 广泛用于京信 2G/3G/4G 传统产品线。伴随 5G 时代的到来,赛灵思 Zynq 7000 SoC、MPSoC、Kintex 系列已广泛应用于京信新一代高效无线产品。

Xilinx 器件及 Vitis/Vitis AI 解决方案可为众多应用加速,包括视频处理、图像预处理、AI 推断以及内存带宽优化等。在本视频中,我们将演示如何使用 Xilinx ZCU104 开发人体检测应用。

近年来,向基于NAND闪存的存储迁移和非易失性存储器快车®(NVMe™)的引入,为技术公司以不同的方式"做存储"增加了许多机会。实时数字业务的快速增长和多样性要求这种创新,以便实现新的产品和服务。本应用说明介绍了BittWare支持FPGA和MPSoC的250系列加速器产品如何用于让客户为下一代物联网和云基础设施构建高性能、可扩展的NVMe基础架构。

计算密集型应用是指需要大量复杂计算的任何计算机应用。像 AI 推理、大数据分析、网络和科学研究建模之类就是如今的一些比较流行的计算密集型应用。Xilinx UltraScale MPSoC 架构提供了多种高级处理器,从 32 位到 64 位,支持虚拟化,并通过“合适的任务使用合适的引擎”理念实现了真正的异构多处理能力。

应用程序不断增多,适用的无线设备也随之增加,造成需求和设计越发复杂。由于人们需要的数据越来越多,硬件设计便向着更宽的带宽、更高的频率和更多的通道发展,而软件则需要提供更大的灵活性,并缩短产品上市时间
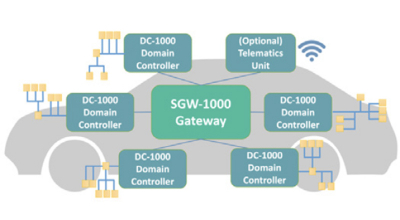
目前,汽车市场对软件定义功能和应用的需求越来越旺盛,行业正迫切需要一种先进的网关,能够提供通用性并为客户提供数据加速和数据分析功能。此外,由于 OEM 车辆和软件定义车辆在需求上存在较大差异,因此需要一种功能更强大且良好平衡的通用型解决方案。

随着人工智能(AI)应用的高速发展,视觉AI成了各家技术公司逐鹿的主战场。基于机器学习,网络边缘的视觉AI设备可以根据AI推理,完成物体探测、人脸识别、图像分析等多种智能视觉任务,为用户带来全新的体验。

2021年计算机视觉挑战赛分别由Facebook和Xilinx各支持一个赛道。在Xilinx的赛道中,主要是是提高研究者在人工智能算法(AI)加速器设计过程中的能量效率意识,同时激发研究人员针对AI加速器优化的新型神经网络架构进行创新性研究和设计。

随着人工智能和机器学习算法取得一系列新进展,众多高计算强度的应用正在被部署到边缘设备上。当下,业界迫切需要一种高效率的硬件,既能高效率地执行复杂算法又能适应这种技术的快速演进。在此背景下,赛灵思 Kria K26 SOM应运而生,为 ML 边缘应用开发提供了更加理想的选择。